Vision-Language-Action models (VLAs) achieve strong performance in general robotic manipulation tasks by scaling imitation learning. However, existing VLAs are limited to predicting short-sighted next-action, which struggle with long-horizon trajectory tasks due to incremental deviations. To address this problem, we propose a plug-in framework named VLA-Reasoner that effectively empowers off-the-shelf VLAs with the capability of foreseeing future states via test-time scaling.
Specifically, VLA-Reasoner samples and rolls out possible action trajectories where involved actions are rationales to generate future states via a world model, which enables VLA-Reasoner to foresee and reason potential outcomes and search for the optimal actions. We further leverage Monte Carlo Tree Search (MCTS) to improve search efficiency in large action spaces, where stepwise VLA predictions seed the root. Meanwhile, we introduce a confidence sampling mechanism based on Kernel Density Estimation (KDE), to enable efficient exploration in MCTS without redundant VLA queries. We evaluate intermediate states in MCTS via an offline reward shaping strategy, to score predicted futures and correct deviations with long-term feedback.
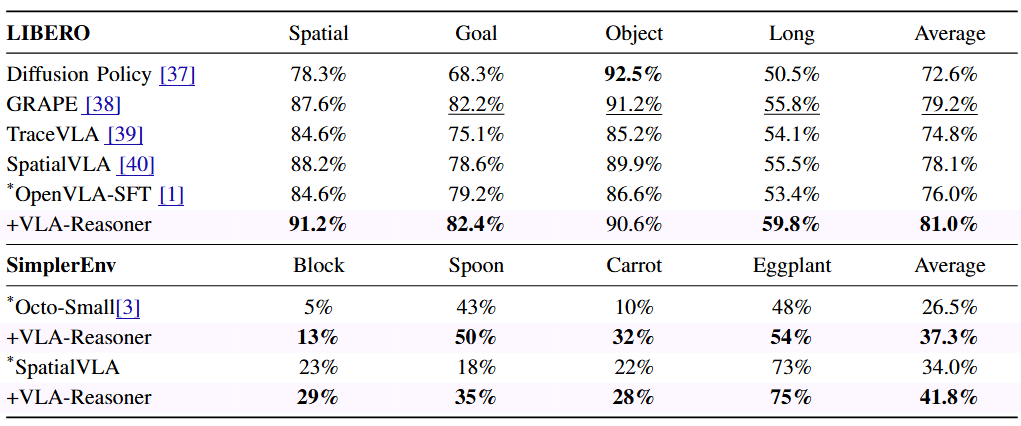
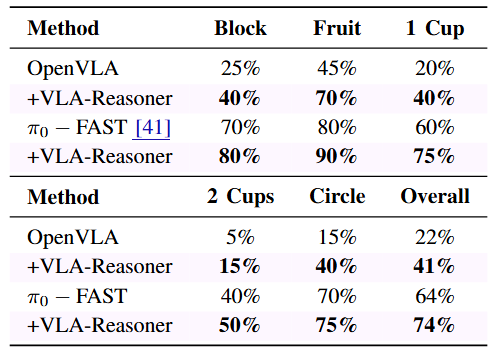
We conducted extensive experiments in both simulators and the real world, demonstrating that our proposed VLA-Reasoner achieves significant improvements over the state-of-the-art VLAs. Our method highlights a potential pathway toward scalable test-time computation of robotic manipulation.